binary search是面试中非常经常被问到的一个题。应该这么说binary search是一个比较简单的算法,但是变形很多,很容易掉到陷阱里面出不来。
废话不说,先看两个题:

这个题应该首先向面试官提问有没有重复
这是我去年面试morgan stanley中遇到的一个题目。诚然对于搜索,最次最次有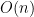
一个自然的想法是如果我们能找到pivot point,那么在pivot point左右两边序列都是sorted的,那么我们在两边分别使用binary search就行了,问题是find_pivot这个算法不能太复杂,最好复杂度也是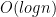
int binary_search(vector<int>& nums,int target,int l,int r){
int mid=(l+r)/2;
if(l>r)
return -1;
if(nums[mid]==target)
return mid;
else if(nums[mid]>target)
return binary_search(nums,target,l,mid-1);
else
return binary_search(nums,target,mid+1,r);
}
int find_pivot(vector<int>& nums){
int l=0;
int r=nums.size()-1;
int mid;
if(nums[0]<nums[nums.size()-1])
return 0;
while(l<r){
mid=(l+r)/2;
if(nums[mid]>=nums[0]){
l=mid+1;
}
else{
r=mid-1;
}
}
return l;
}
int search(vector<int>& nums, int target) {
if(nums.size()==0)
return -1;
int pivot=this->find_pivot(nums);
int idx1=this->binary_search(nums,target,0,pivot);
int idx2=this->binary_search(nums,target,pivot,nums.size()-1);
if(idx1==-1 && idx2==-1)
return -1;
if(idx1 !=-1){
return idx1;
}
if(idx2 !=-1){
return idx2;
}
return -1;
}
基本就是按照我们的思路写下来的,难点是如何写binary search.一般来讲binary search 由三个部分构成:
- 定义中间点mid
- 定义左起点和右起点 l和r,以及更新方式,一般地l或者r都要个加一或者减一
- 定义终止循环条件,一般有两种 while(l<r),第二种是while(l<=r), 另一种是while(l<r),具体选择使用那一种主要看l==r这个条件我们是不是要退出,如果要,就将条件设置成l<r。同时要注意,最后返回的时候注意l=mid+1,最后返回l就行。
另外有一点要说明的是,binary_search一般有两种实现方式,一种是使用循环,另一种是使用递归。我们一般都选择使用循环来实现,因为递归实在是too subtle了。当然,如果是vallina形式的binary search可以选择使用递归。
这里要说明的是这样一行代码if(nums[mid]>=nums[0])。请注意,这里是大于等于不是大于。这里我也没有想明白为什么。事实上,关于这些边界问题,我真的没有统一答案,只能一个一个试错了。

![\Sigma_{k=i}^{j}A[k]](https://s0.wp.com/latex.php?latex=%5CSigma_%7Bk%3Di%7D%5E%7Bj%7DA%5Bk%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,然后在得出最大值就可以了,这样做的复杂度是
,然后在得出最大值就可以了,这样做的复杂度是 。既然这样,我们不禁要问,能不能扫描一次就得出结果呢?
。既然这样,我们不禁要问,能不能扫描一次就得出结果呢?![S[i]=\Sigma_{k=}^{i}A[i]](https://s0.wp.com/latex.php?latex=S%5Bi%5D%3D%5CSigma_%7Bk%3D%7D%5E%7Bi%7DA%5Bi%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,就是前i项的和,那么对于每个i,S[i]是固定的,接下来我们需要确定起点j从而最大化
,就是前i项的和,那么对于每个i,S[i]是固定的,接下来我们需要确定起点j从而最大化![\Sigma_{k=j}^{i}A[k]](https://s0.wp.com/latex.php?latex=%5CSigma_%7Bk%3Dj%7D%5E%7Bi%7DA%5Bk%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,也就是说,如果我们最小化S[j],那么S[i]-S[j]就是以i为终点的max subarray sum。我们遍历i取出最大值就可以了。代码如下:
,也就是说,如果我们最小化S[j],那么S[i]-S[j]就是以i为终点的max subarray sum。我们遍历i取出最大值就可以了。代码如下: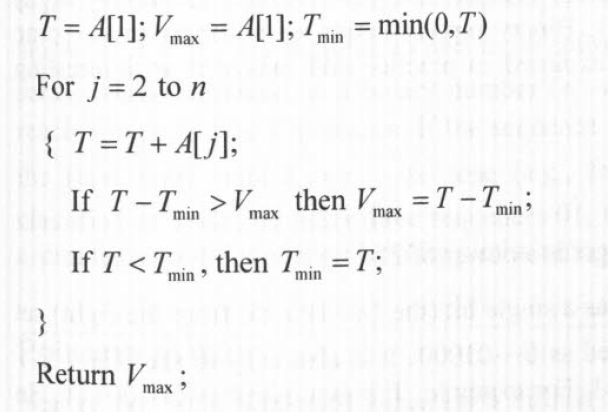


 。当然也可以选择forward selection,这样可以把复杂度降低到
。当然也可以选择forward selection,这样可以把复杂度降低到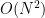 。
。